
ЙиМќзж ЗЧБШНЯЃЛВщевЃЛХХађЃЛЪБМфИДдгЖШЃЛМЦЪ§ЃЛећЪ§
1 ЫуЗЈЕФЛљБОЫМЯы
ЭЈГЃЕФХХађЫуЗЈдкПеМфКЭЪБМфИДдгЖШвЛЖЈЕФЧщПіЯТЕФЪБМфПЊЯњжївЊЪЧЙиМќзжжЎМфЕФБШНЯКЭМЧТМЕФвЦЖЏЁЃЛљгкМЦЪ§ХХађЕФВщевЫуЗЈЃЈCount-SearchЃЉЕФЪЕЯждкећИіЙ§ГЬЮоашНјааЪ§ОнЕФБШНЯЃЌЫуЗЈЕФЪБМфИДдгЖШЮЊO( 2*N )ЁЃИУЫуЗЈЕФЛљБОдРэЪЧЃК
ИљОнЮоЗћКХећЪ§ЕФДѓаЁПЩвдКЭЪ§зщдЊЫиЕФЯТБъЖдгІЕФддђЃЌдкГЬађжаПЩвдгУећЪ§Ъ§зщРДДЂДцдЊЫиЕФДѓаЁЙиЯЕЁЃЖдгквЛИіДѓаЁЮЊNЕФећаЭЪ§зщa[]ЃЌЖдгкУПвЛИідЊЫиxЃЌгУЪ§зщжаЕФдЊЫиa[x]МЧТМЯТаЁгкЕШгкЫќЕФдЊЫиИіЪ§ЃЌЕБвЊевЕФЪЧМЏКЯжаЕкKИіДѓЕФдЊЫиЪБЃЌдђжЛашевЕНИУЪ§зщжаЕкN-K+1аЁЕФдЊЫиЁЃМДжЛашвЊевЕНИУЪ§зщжаЕквЛИіДѓгкЛђЕШгк N-K+1ЕФдЊЫиЃЌИУдЊЫиЕФЯТБъМДЮЊЕкKДѓЕФЪ§ЁЃ
ИУЫуЗЈОпЬхПЩвдУшЪіЮЊЃКМйЩшnИіЪфШыдЊЫиЕФУПвЛИіЖМЪЧНщгк0ЕНMжЎМфЕФећЪ§ЃЌДЫДІMЮЊФГИіЮоЗћКХећЪ§ЁЃ
(1) ЖдгкУПвЛИіЪфШыЕФдЊЫиXЃЌЪзЯШШЗЖЈГіЕШгкXЕФдЊЫиИіЪ§ЁЃ
(2) ЖдгкУПвЛИідЊЫиXЃЌШЗЖЈаЁгкЕШгкXЕФдЊЫиИіЪ§ЁЃ
(3) ДгЪ§зщЪзЕижЗГіЗЂЫГађВщевЕНЕквЛИіаЁгкЕШгкKЕФдЊЫиЃЌдђИУдЊЫиXМДЮЊЫљвЊВщевЕФЕкKаЁЕФЪ§ЃЌЫГађВщевЕНЕквЛИіаЁгкЕШгкN-K+1ЕФдЊЫиЃЌдђИУдЊЫиXМДЮЊЫљвЊВщевЕФЕкKДѓЕФЪ§ЁЃ
2 МЦЪ§ВщевЫуЗЈЕФCгябдЪЕЯж(Count—Search)
2.1 Ъ§ОнНсЙЙЕФЩшМЦгыГЬађ
МйЖЈЪфШыЕФЪ§зщЮЊећаЭЪ§зщA[1..N]ЃЌlength[A]=NЃЌЪ§зщжадЊЫизюДѓжЕЮЊMЃЌЪ§зщC[]МЧТМећЪ§дЊЫиЕФДѓаЁЙиЯЕЁЃ
Count-Search(int* AЃЌint K)
memest(CЃЌ0)//C[0..M]==0ГѕЪМЛЏC[]
for j=1 to length[A]
do C[A[j]]=C[A[j]]+1
//C[i]АќКЌЕШгкiЕФдЊЫиИіЪ§
for i=1 to M
begin
do C[i] = C[i]+C[i-1] //C[i]АќКЌаЁгкЕШгкiЕФдЊЫиИіЪ§
if( C[i]>= N-K+1 ) breakЃЛ//бАевЕНЕкN-K+1ЕФдЊЫиЃЌМДЮЊЕкKДѓЕФдЊЫи
end
2.2 ЫуЗЈВНжшЗжЮі
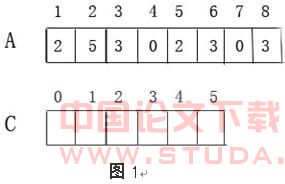
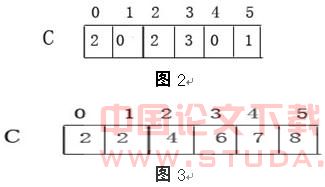
ЕквЛВНЃКЕквЛааЕФГѕЪМЛЏВйзїжЎКѓЃЌдк2-3ааМьВщУПвЛИіЪфШыдЊЫиЁЃШчЙћвЛИіЪфШыдЊЫиЕФжЕЮЊiЃЌМДC[i]ЕФжЕМг1 ЁЃгкЪЧдкЕк3аажЎКѓЃЌC[i]жаДцЗХСЫЕШгкiЕФдЊЫиИіЪ§ЃЈећЪ§i=0ЃЌ1ЃЌ…MЃЉЁЃ
ЕкЖўВНЃКдкЕк4-8жЎКѓЃЌC[i]ДцЗХСЫаЁгкЕШгкiЕФдЊЫиЕФИіЪ§ЁЃзюКѓДгЪ§зщCЕФЪзЕижЗГіЗЂЫГађВщевЕквЛИіЪЙЕУC[i]>=N-K+1ЕФдЊЫиЃЌдђЕкKДѓЕФдЊЫиМДЮЊi ЁЃ
ЯТЭМИјГіСЫCount-SearchЕФдЫЫуЙ§ГЬЃКЭМ1БэЪОГѕЪМЪ§зщAЃЌCЁЃЭМ2БэЪОдЫааЭъГЬађ 2-3ааЃЌЪ§зщCжаЕФдЊЫиC[i]ДцЗХЕФЪЧЪ§зщAжаЕШгкiЕФдЊЫиИіЪ§ЁЃЭМ3БэЪОдЫаа4-8ааЕФНсЙћЃЌCжадЊЫиC[i]ДцЗХЕФЪЧЪ§зщAжааЁгкЕШгкiЕФдЊЫиИіЪ§ЁЃР§ШчВщевИУЪ§зщЕк3ДѓЕФЪ§ЃЌдђгЩгкC[2]=4>=3ЃЌЙЪдЊЫи2МДЮЊЫљвЊВщевЕФЕк3ДѓЕФЪ§ЁЃ
2.3 ЪБМфИДдгЖШЗжЮі
ГЬађ2-3ааЪБМфИДдгЖШЮЊO(N)ЃЌЕк4-8ааЪБМфИДдгЖШЮЊO(M)ЃЌИУЫуЗЈЕФЪБМфИДдгЖШЮЊT(n)= O( N+M)ЁЃШчЙћЪ§зщA[]ЕФзюДѓжЕMгыNГЩЯпаЮЙиЯЕЃЌМДM=O(n)ЃЌдђЦфЪБМфИДдгЖШЮЊT(n) = O( 2N)ЁЃ
3 Count-SearchЫуЗЈгыDivide-SelectЫуЗЈЕФБШНЯ
Divide-Select ЕФЛљБОЫМЯыЪЧЃКЭЈЙ§дкЯпадЕФЪБМфФкевЕНвЛИіЛЎЗжЛљзМЃЌЪЙЕУАДетИіЛљзМЫљЛЎЗжГіЕФСНИізгЪ§зщЕФГЄЖШЖМжСЩйЮЊдЪ§зщЕФξБЖЃЈ0<ξ<1ЪЧФГИіе§ГЃЪ§ЃЉЃЌШЛКѓЖдзгЪ§зщЕнЙщЕФЕїгУDivide-SelectЫуЗЈЃЌетбљОЭПЩвддкЯпадЕФЪБМфФкЭъГЩВщевШЮЮёЁЃ[6]
ИУЫуЗЈЕУЪБМфИДдгЖШЮЊO(6.09*N)[5]ЃЌгыCount-SearchЫуЗЈЯрБШНЯПЩжЊЃКCount-SearchЫуЗЈОпгаИќКУЕФЪБМфИДдгЖШЁЃ
4 ЫуЗЈВтЪдгыБШНЯ
ЮЊСЫжЄЪЕЩЯЪіНсТлЃЌдкACER TravelMate 2420 (PM730ЃЌ512MФкДцЃЌ80GгВХЬ)ЃЌWindows XP ЦНЬЈЩЯБраДСЫШ§жжВщевЫуЗЈЕФзгГЬађЃЌНјааСЫЯргІЕФЪЕбщВтЖЈЃЌЦфНсЙћШчБэ1 ЫљЪОЁЃЃЈЪЕбщЪ§ОнШЋВПВЩгУОљЗжВМЕФЮоЗћКХећаЭЫцЛњЪ§ЃЉ
Бэ1
|
Ъ§ОнЙцФЃ
|
2*10^5
|
8*10^5
|
10^6
|
2*10^6
|
8*10^6
|
10^7
|
8*10^7
|
|
ПьЫйХХађЕФВщевЃЈqsortЃЉ
|
63
|
219
|
265
|
579
|
2203
|
2766
|
62437
|
|
Divide- Select
|
31
|
109
|
140
|
329
|
1157
|
1347
|
11732
|
|
Count-Search
|
15
|
16
|
31
|
31
|
187
|
203
|
1344
|
зЂЃКвдЩЯЪБМфЕЅЮЛЮЊКСУыMSЁЃ
ИљОнвдЩЯЪ§ОнЮвУЧПЩвдЛцжЦГіЪ§ОнЙцФЃКЭЪБМфЕФКЏЪ§ЭМЯёЁЃ
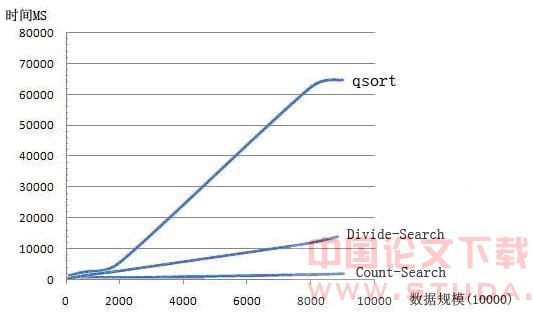
ЙлВьЗжЮівдЩЯЪЕбщНсЙћЃЌПЩвдПДГіЃКЛљгкПьЫйХХађЕФВщевЫуЗЈКЭЦфЫћЫуЗЈЯрБШНЯОпгаНЯВюЕФаЇТЪЃЛЖјВЩгУСЫЗжжЮВпТдЕФDivide- SelectВщевЫуЗЈЕФаЇТЪПЩвдЪЧЛљгкПьЫйХХађЕФВщевЫуЗЈЕФМИЪЎБЖЃЌЦфЪБМфИДдгЖШдкЭМжавВЗДгГЮЊЯпадЁЃЖјЛљгкМЦЪ§ХХађЕФВщевЫуЗЈЃЈCount- SearchЃЉЕФЪБМфИДдгЖШЭЌбљДяЕНСЫЯпадЃЌЕЋЪЧаЇТЪШДБШDivide-SelectИќИпЃЌЭЈЙ§ЩЯЪіЪЕбщПЩвдЕУжЊЃКдкНјааЮоЗћКХећЪ§ВщевЪБЃЌЛљгкМЦЪ§ХХађЕФВщевЫуЗЈЃЈCount-SearchЃЉдкЪБМфЩЯЪЧзюгХЕФЁЃ
5 Count-SearchЕФгІгУЗЖЮЇ
дкВщевЮоЗћКХећЪ§МЏКЯЪБЃЌгІгУCount-SearchЫуЗЈЃЌФмЙЛНЕЕЭВщевЪБМфИДдгЖШЁЃЕЋЪЧгІгУCount-SearchЫуЗЈЪБвЊзЂвтЃКИУЫуЗЈжЛЪЪгУгкећЪ§ЕФВщевЃЌЧвВщевМЏКЯSЕФзюДѓжЕMгыSжадЊЫиИіЪ§NВЛГЩжИЪ§ЙиЯЕЃЌМДM ВЛФмдЖДѓгкNЁЃвђЮЊЕБMЙ§ДѓЪБЃЌЪзЯШФкДцПЊЯњОЭЛсКмДѓЃЌЦфДЮЪБМфИДдгЖШвВЛсЯргІЕФЬсИпЁЃ
ИУЫуЗЈГфЗжЕФдЫгУСЫећЪ§ЕФЬиадЃЌећИідЫЫуЙ§ГЬжаЮоашЪ§ОнЕФБШНЯКЭНЛЛЛЃЌДѓДѓНЕЕЭСЫЫуЗЈЕФЪБМфИДдгЖШЃЌвђДЫИУЫуЗЈПЩвддкЙЄГЬЭГМЦжаЕУЕНДѓЙцФЃдЫгУЁЃР§ШчЃКЫцзХЭјТчЕФЗЂеЙКЭгІгУЃЌЭјТчжаЕФаХЯЂСПГЩБЖЕФРЉДѓЃЌЖјдкЦфжаЮвУЧЙизЂЕФзюЖрЕФдђЪЧЭГМЦХХУћБШНЯППЧАЕФаХЯЂЃЌШчЙћНЋШЋВПЙ§вкЕФЭГМЦСПХХађЃЌдђгЩгкЪ§ОнСПЙ§ДѓЃЌдђЛсРЫЗбДѓСПЕФЪБМфКЭзЪдДЁЃЖјВЩгУCount-SearchЕФВщевЫуЗЈЃЌОЭПЩдкЯпадЕФЪБМфЭъГЩЁЃ
6 НсЪјгя
БОЮФжаЬсГіЕФвЛжжЛљгкМЦЪ§ХХађЫуЗЈЕФећЪ§ВщевЫуЗЈЃЌИУЫуЗЈдкдЫЫуЙ§ГЬжаЮоашНјааЪ§ОнЕФБШНЯКЭНЛЛЛЃЌИУЫуЗЈПЩвдгІгУЕНДѓЙцФЃЕФећЪ§ВщевЃЌЫуЗЈЕФЪБМфИДдгЖШКмЕЭЃЌЖјЧвБмУтЕФДѓСПЕФЪ§ОнБШНЯКЭНЛЛЛЃЌЭЌЪБдкЪБМфЩЯЪЧзюгХЕФЁЃ
ВЮПМЮФЯз
[1]ДодѓХєЃЌРюЮАЩњ. EREW PRAMФЃаЭЩЯжИЪ§МЖЗжИюД§ДІРэЪ§ОнМЏЕФВЂааЖрбЁЫуЗЈ[J].ББЗННЛЭЈДѓбЇбЇБЈЃЌ2003ЃЌ(2)ЃК46-49
[2]АржОНмЃЌИпЙтРД. вЛжжByteВщевЕкKИідЊЫиЕФЫуЗЈбаОП[J]. ФкУЩЙХДѓбЇбЇБЈЃЌ2004ЃЌ(3)ЃК322-324
[3]Thomas H.Cormen Charles E.Leiserson. ЁЖЫуЗЈЕМТлЁЗ[M]. ББОЉЃКЛњаЕЙЄвЕГіАцЩчЁЃ2006.9ЃК98-99
[4]Muhammad H.Alsuwaiyel. An optimal parallel algorithm for the multiselection problem[J]. Parallel ComputingЃЌ2001ЃЌ(27)ЃК861—865
[5]НЛЊ. ЧѓЕкKИідЊЫиЕФПьЫйХХађЫуЗЈ[J]. ЩиЙибЇдКБЈЃЌ2003ЃЌ(6)ЃК32-34
[6]ЭѕЯўЖЋ.ЁЖЫуЗЈЩшМЦгыЗжЮіЁЗ[M] .ББОЉЃКЧхЛЊДѓбЇГіАцЩчЃЌ2003.1ЃК39-43



